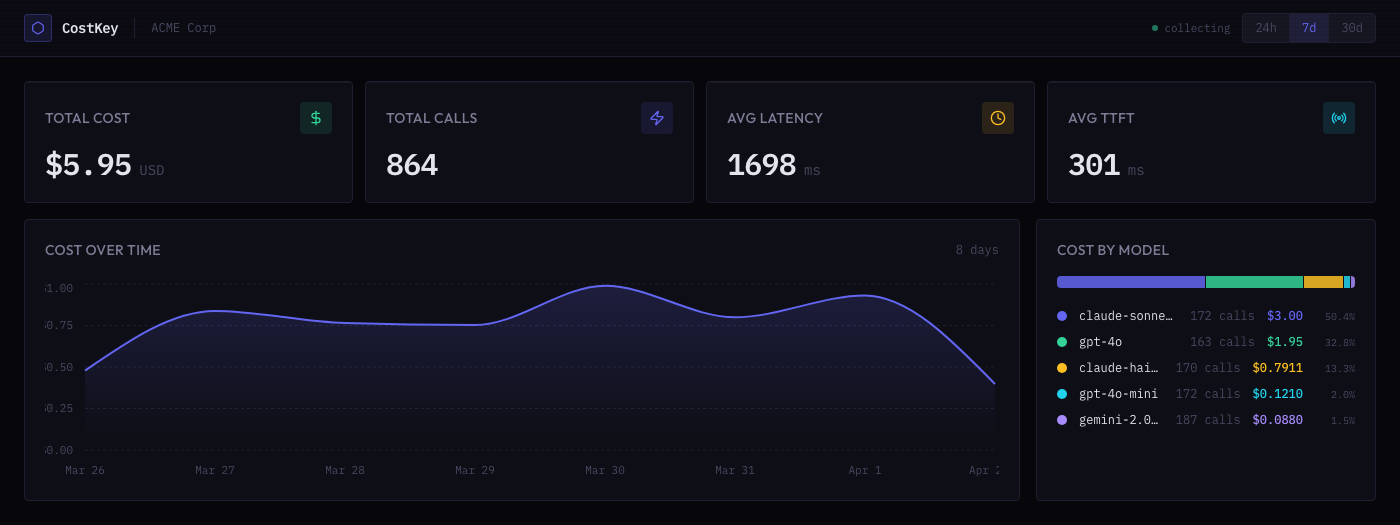
AI costs, down to the function.
Your OpenAI dashboard says you spent $2,000. CostKey tells you generateSummary() in src/features/search.ts:47 spent $1,200 of that — with one CLI command.
Open source SDKs on GitHub · npm + PyPI
Node
Python
1npx costkey setup
1pipx run costkey setup
Works with 15 providers · Zero config
 OpenAI
OpenAI
 Anthropic
Anthropic
 Google
Google
 Groq
Groq
 xAI
xAI
 Mistral
Mistral
 DeepSeek
DeepSeek
 Cohere
Cohere
 Together
Together
 Fireworks
Fireworks
 Perplexity
Perplexity
 Cerebras
Cerebras
 OpenRouter
OpenRouter
 Bedrock
Bedrock
 Azure
Azure
Already using Portkey, Helicone, or LiteLLM? CostKey runs on top. Same setup command. No proxy changes.